TL;DR
We make iterative refinement actually work for non-autoregressive LMs.
- The Problem: Discrete diffusion models promise iterative refinement, but sampling independent marginals causes factorization error and collapses performance. The generate, erase, repeat loop becomes infeasible when every single generation takes several function evaluations.
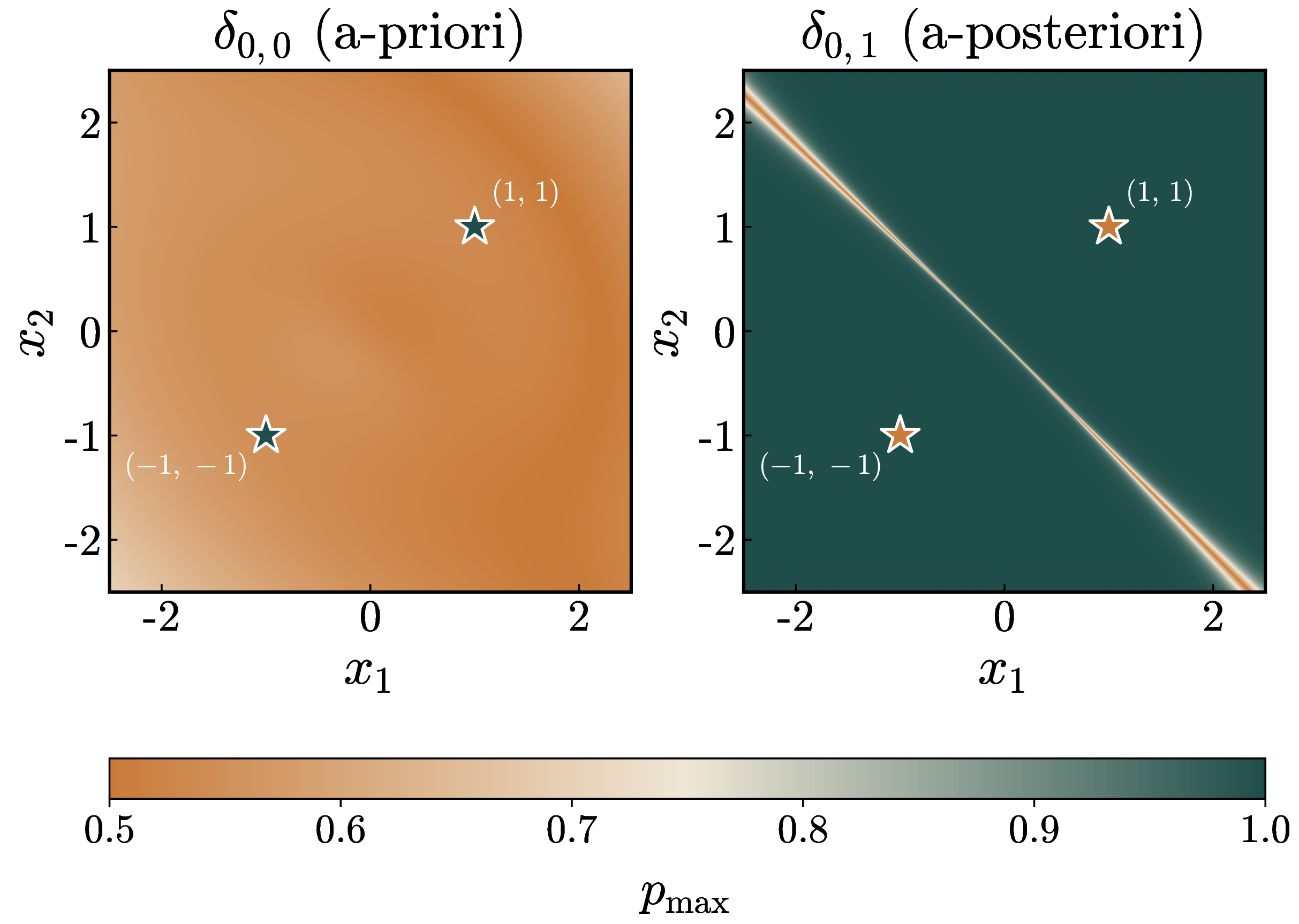
- The Missing Piece: Flow Map Language Models (FMLMs) fix this factorization error via joint transport between Gaussian noise and one-hot data.
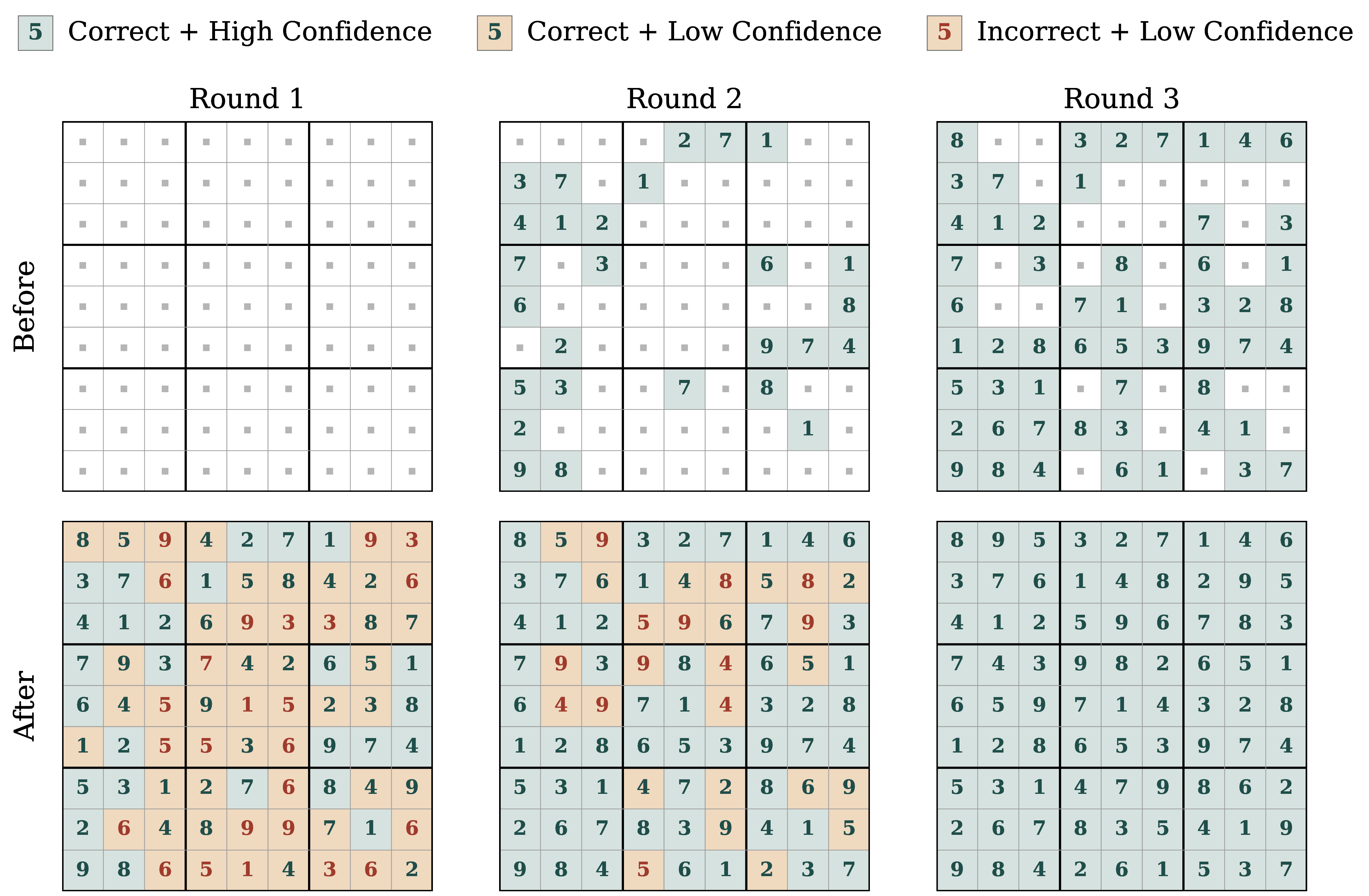
- The Solution: We put it all together. Masking-style FMLM enables Posterior Refinement, letting the model self-correct based on a full draft sequence with a novel a posteriori confidence signal.
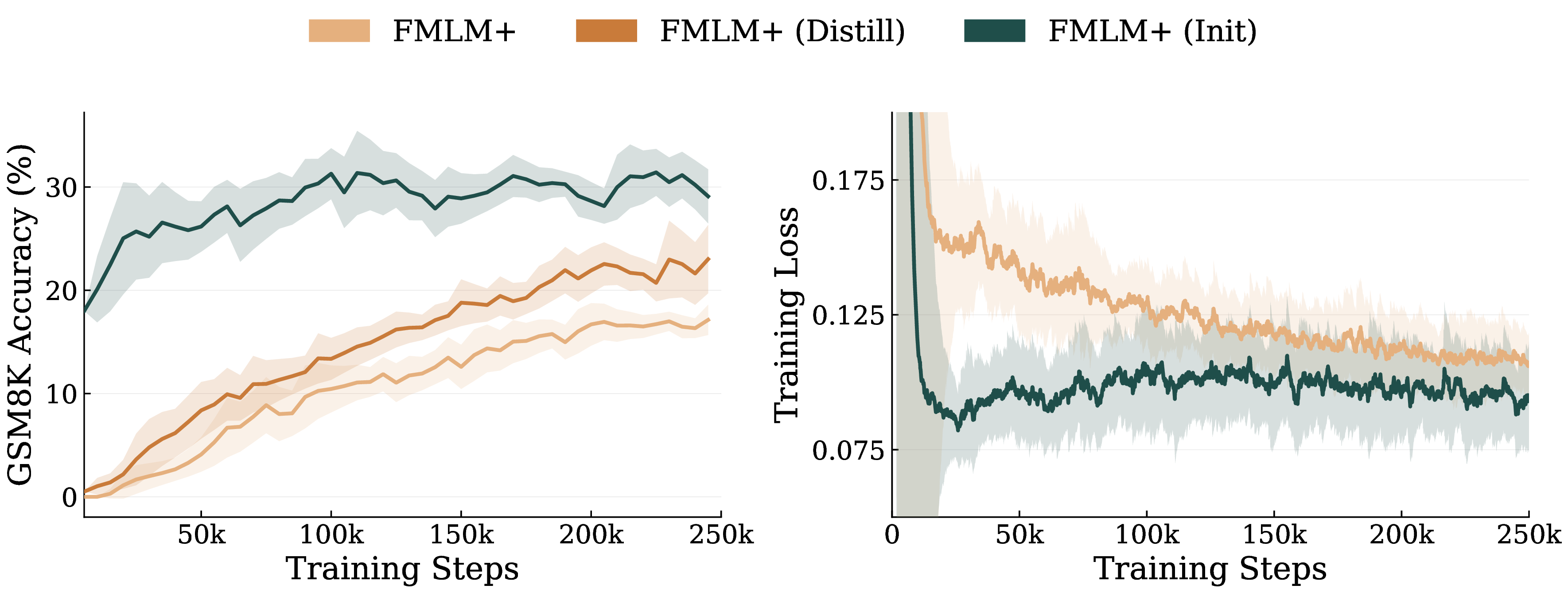
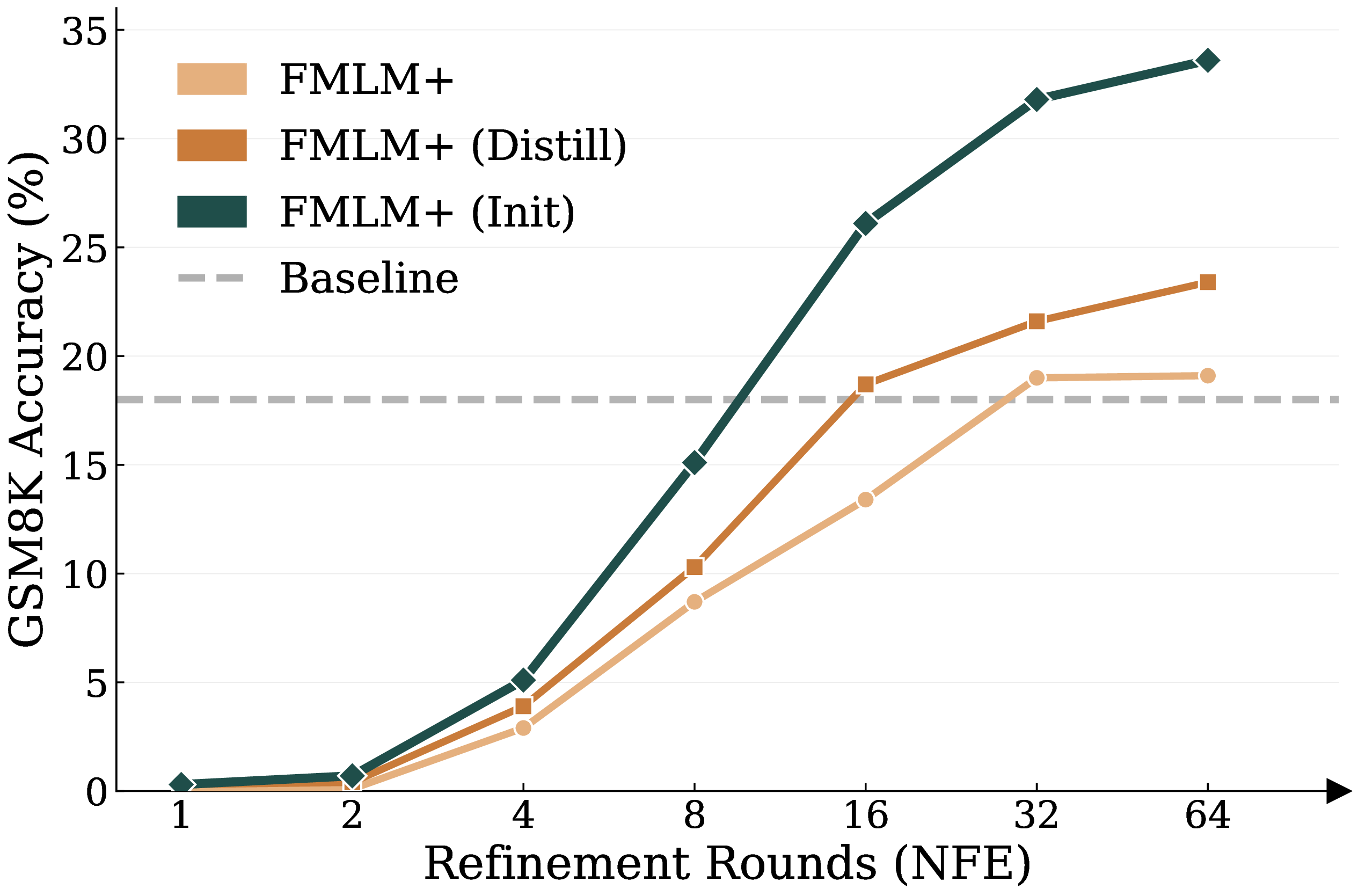
- The Result: SOTA speed-quality tradeoff, matching discrete baselines with 32× fewer NFEs.
Abstract
Non-autoregressive generation offers a powerful paradigm for iterative refinement, allowing models to recursively critique, erase and regenerate arbitrary subsets of tokens. However, existing non-autoregressive models fail to realize this potential. Masked Diffusion Models (MDMs) suffer from factorization error, causing sample quality to collapse when generating multiple tokens simultaneously. Flow Map Language Models (FMLMs) circumvent this bottleneck via joint sequence transport for excellent few-step generation, but sacrifice the inference-time flexibility of MDMs.
We introduce FMLM+, a framework that bridges this gap by equipping FMLM with masking-style noise schedules. While generating the full sequence in a single step, FMLM+ simultaneously scores the global consistency of each token a posteriori. We leverage this to introduce Posterior Refinement, a novel inference-time refinement strategy that enables the model to adaptively self-correct its outputs, matching the performance of discrete baselines with 32× fewer NFEs. Across diverse benchmarks, we demonstrate that FMLM+ with Posterior Refinement improves the speed–quality tradeoff over both MDM and FMLM families, providing a scalable foundation for high-fidelity language modeling.